Designing Data-Intensive Application 第五章筆記
資料副本(Replication)的意思是透過網路,將資料複製到多個節點(機器)上面儲存。Replication 有以下三個好處:
- 讓資料在地理位置上靠近使用者以降低 network latency。
- 當部分節點不可用時系統依然可以保持運作,提高可用性(Availability)。
- 分散 read queries,提高 read throughput。
Replication 的難處在於資料是會更新的,因此如何透過網路同步這些資料的更新是最大的難點。本章節主要探討三種常見的 replication model,分別是 single-leader replication、multi-leader replication 以及 leaderless replication。
Leader and Followers
首先,只要每個 writes 都能被每個 replica 按照一樣的順序執行,那麼最後每個 replica 都會擁有相同的資料。
因此最常見的 replica 方式即將某個節點視為 leader,所有的 client writes 都只能送給 leader,在 leader 確認資料寫入其本地的儲存後,由 leader 透過 replication log 或是 stream 向其他的 replicas(稱作 followers)送出資料變更的請求。每個 followers 只要在收到更新的 log 後按照與 leader 一樣的順序更新其本地的儲存即可。
而 client 雖然只能寫入到 leader,但是可以透過 leader 或是 followers 來讀取。
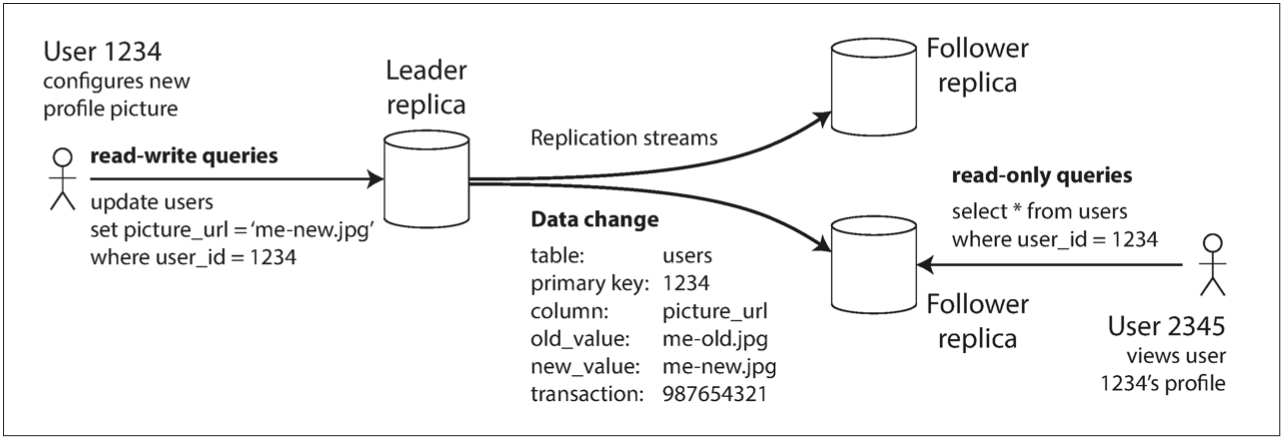
Leader-follower 模式可以透過讀寫分離來大幅降低資料庫的 loading,並且一般多數的 web application 都是 read-heavy 的,因此在 PostgreSQL、MySQL、MongoDB 等常見的 databases、或是 Kafka、RabbitMQ 等 message queue systems 中,leader-based replication 都是內建的 features。
Synchronous Versus Asynchonous Replication
在 replication 的過程中,可以發現從 leader 寫入到 followers 寫入中間會有一段 delay。
在 relational database 中,可以選擇使用 synchronous 或是 asynchronous 的方式來做 replication。
- Synchronous Replication:Leader 等到 followers 回覆資料寫入後才讓寫入可見並且回傳成功。
- Asynchronous Replication:Leader 確認寫入到本地儲存空間後立刻回傳成功。
Synchronous 的好處能夠確保資料的一致性(Consistency),壞處是當 followers failure 時資料就無法寫入,降低系統的可用性(Availability)。
因此所有的 followers 都使用 synchronous replication 是不可行的,否則一個 follower 的 outage 就會導致所有寫入無法執行。常見的配置包括:
- 只有一個 follower 採用 synchronous,其他 followers 採用 asynchronous。有時稱作 semi-synchronous 的設定。
- 全部的 followers 都是 asynchronous,可能會造成資料的遺失(寫入到 leader 後 leader failure,則這筆 commit 無法被提交到其他的 followers 而消失)。
Setting Up New Followers
要在 zero-downtime 的情況下增加新的 follower,首先取得 leader 在某個時間點的 snapshot 並複製到 follower node 中,follower 開始向 leader 請求 snapshot 後的 replication log,例如 log 的索引值在 PostgreSQL 中稱作 LSN,最後同步完成。
Handling Node Outages
Follower failure: Catch-up recovery
在 follower 的本地儲存中有紀錄哪些 commit 已經完成的 log,因此當 follower 重啟時可以從最後一個完成的 transaction 開始向 leader 請求所有的變更。
Leader failure: Failover
Leader failure 後某個 follower 需要晉升成 leader,這個過程稱作 failover。
Failover 的過程包含以下幾個步驟:
- 偵測 leader 是否還正常運作:通常透過 heartbeat 與 timeout 達成。
- 選擇一個新的 leader:通常稱作 leader election,新的 leader 最好的選擇是擁有最新資料的 follower。要讓所有 followers 取得新 leader 的共識是一個 consensus problem,會在後面的章節介紹到。
- 重新設置系統:要讓 client 端、舊的 leader、其餘 followers 都能夠知道有新的 leader 以及新的 leader 是哪個節點。
其中有一些重要的問題要注意:
-
採用 asynchronous replication 可能導致資料的遺失,違反 durability 的原則。
-
就算 durability 的問題可以被允許,也要小心丟棄 writes 可能造成的問題。
例如使用 autoincrementing ID 後,若新的 leader 使用到一些舊 leader 使用過的 ID,可能導致儲存在 Redis 快取中 ID 對應到的資料與 DB 中的資料不符而導致讀取到錯誤的資料(可能造成資料外洩)。
-
要小心 split brain 的發生,也就是有兩個 nodes 任為自己是 leader 並同時接收 client 的寫入。
-
Heartbeat timeout 的時間如果過短,會造成不必要的 failover(leader 可能只是 response time 增加);過長會造成系統花更久的時間 recovery。
Implementation of Replication Logs
關於 replication logs 的實作有以下幾種:
Statement-based replication
將修改相關的 statement 複製到 follower nodes,例如 SQL 中就是 INSERT、UPDATE 與 DELETE。這種方法會有一些問題:
- Nondeterministic functions 會得到不一樣的結果:例如
NOW()或是RAND()。 - 一些 statements 的順序將不能改變,例如
INSERTautoincrementing column,或是基於一些欄位的UPDATE。這會限制原本可以並行的 transactions 使他們一定要串行的執行。
所以 leader 需要先將 nondeterministic statement 都先變成 deterministic log 才能送給 follower nodes。因此這個方法只有在少數情境下使用,例如 MySQL v5.1 之前。
Write-ahead log (WAL) shipping
Followers 透過讀取 leader 的 WAL 來同步資料。被 PostgreSQL 以及 Oracle 使用。
如此一來完全可以解決 statement-based replication 的問題,但是壞處是 WAL 是非常底層的格式,通常是紀錄 disk 的哪個 block 的數值變化。因此基本上跨版本之間的 WAL 是很有可能不相容的。
如果 WAL 可以跨版本相容,那可以被用在 zero-downtime 升級。先將 followers 都升級後,再讓 leader failover 即可。
Logical log replication
透過額外的 log 提供給 follower 使用,例如 MySQL 的 binlog。
因為 logical log 與 storage engine 使用的格式完全不同,因此適合提供給外部的服務使用,例如寫到 warehouse 或是同步到其他 database 等等。這種技術被稱作 capture data change。
Trigger-based replication
使用 database 的 trigger 註冊一個 application layer 的函數,讓資料更新時自動的呼叫。
適合用在更彈性、更複雜的 replication 上,但是 overhead 較大。
例如 Databus for Oracle、Bucardo for Postgres。
Problems with Replication Log
Replicaiton 提供 fault-tolerance、提升 scalability 以及降低 network latency(地理位置上)。
採用 leader-based replication 可以透過增加 followers 的數量提升 read scability,並且大多數網路應用程式都是 read-heavy 的。就如同前面提到的,使用 leader-based replication 必須採用 asynchronous 的模式,否則單一節點故障會使得整個系統無法運作。
而後面介紹到的 multi-leader replication 或是 leaderless 也都採用 asynchronous 來保證 availability。
採用 asynchronous 模式可能會讀到尚未更新的資料,造成資料庫間暫時的不一致(data inconsistency)。如果對資料庫的寫入停止,那 followers 終究會更新並且達到一致,這就是所謂的 最終一致性 eventual consistency。
以下探討 eventual consistency 造成的幾個問題:
Reading Your Own Writes
使用者送了一筆更新,但是下次讀取時沒有讀到。
若想要達到 read-your-writes consistency or read-after-writes consistency 來避免這個問題,可以:
- 當使用者讀取自己可以修改到的資料時,從 leader 讀取。例如個人資料只有使用者本人可以修改,因此只要是本人讀取時皆從 leader 讀取。但若資料可以被大多使用者修改則不適合這種方式(會變成每個 requests 都要從 leader 讀取)。
- 由 client 提供上次 write 的時間,則 server 只回傳再這個時間之後的結果。若當前的 follower 還沒有更新到這個時間點,可以轉交 requests 給其他 followers 或是多等待。但如果使用者從多個裝置上操作,這個方法將難以達到。
Monotonic Reads
若同一個使用者前後兩次 requests 讀到不同的 followers,可能造成第一次的 request 讀到比第二次 request 還要新的資料。
若想要達到 monotonic reads consistency 來避免這個問題,可以讓同一個使用者永遠都只讀到同一個 replica,例如透過 hash user ID 來決定讀取的 replica,但這樣就必須考慮 replica failed 的時候這些 requests 要如何 re-route 到其他 replica 的問題。
Consistent Prefix Reads
有因果關係的兩個更新,讀取時要保留相同的順序。
這個情況在 single-leader replication 並不會發生,只有在資料庫有 partitioned 並且兩個更新被寫入到不同資料庫時才會發生。因此我們需要一些方式來追蹤有因果關係的寫入,方法會在本章節的後面提到。
Solutions for Replication Lag
因此在使用 eventual consistency 的資料庫時,開發者必須思考這些 replication lag 會不會帶來問題。若有問題的話,則應該要考慮提供更強的 consistency。
最後,如果你喜歡這篇文章,或是文章對你有幫助的話,可以幫我按個喜歡、或是留言!你的支持就是我寫作的最大動力。有任何想問的問題也可以在底下留言喔~
Multi-Leader Replication
Single-leader replication 的主要缺點是所有的 write operations 都要透過 leader。
一個簡單的想法就是使用多個 leaders,每個 leader 並且每個 leaders 都要把收到的 writes forward 給其他節點。
Use Cases for Multi-Leader
多個 datacenter 的操作即是一個很適合 multi-leader replication 的應用場景。
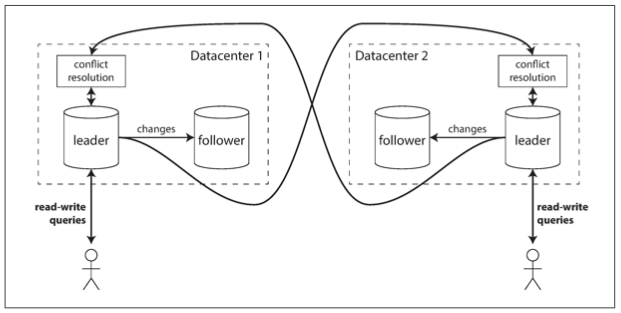
可以考慮每個 datacenter 中只有一個 leader,在一個 data center 內使用 single-leader replication。而 datacenters 之間由 leader 複製 writes 給其他的 leaders。
Multi-leader replication 比 single-leader replication 好的地方在於:
- Performance:若 datacenters 是跨國的,則可以選擇最近的 datacenter 進行讀寫大幅降低 network latency。
- Tolerance of datacenter outages:可以容忍整個 datacenter 的 failover。
- Tolerance of network problems:當 server 與 leader 之間有 network problems 時可以直接寫入到其他 leaders。
使用 Multi-leader replication 最大的缺點在必須處理 concurrent writes,包含 conflict detection、conflict avoidance 以及 conflict resolution。這部分會在接下來的篇幅中提到。
一些 database 是可以透過外部工具支援 multi-leader replication,例如 BDR for PostgreSQL。
Handling Write Conflicts
假設兩個使用者同時對一個值做修改,而一個修改被成功寫到 leader 1,另一個修改被成功寫道 leader 2,這時就會產生衝突。要處理 write conflicts 有以下幾種方式:
-
Detect conflicts:可以透過 lock write operations 來偵測 conflicts,但是在 multi-leader replication 下使用 global lock 會喪失 multi-leader replication 的主要優點。
-
Avoid conflicts:
- 確保資料不會在兩個 datacenter 同時寫入(要考慮在兩地的 user 有多大機率寫入同一筆資料,若機率很小則適合)。
- 利用 routing 使得同樣的資料被寫入到同一個 leader。壞處是對於同一筆資料來說其實就是 single-leader replication。
-
Resolve conflicts:
以下是幾種可能發生的 conflicts 與常用的解決方案:-
寫入同一筆資料:
- Last write wins (LWW):注意分散式系統下時間是不可靠的,可能會需要使用 logical clock。並且 last write wins 代表有 data loss 的可能性。
- Perserve all (MVCC):保留全部的資訊並且交由 application layer 來解決衝突。
LWW 與 MVCC 會在 Leaderless Replication 中大量被使用並介紹。
-
Autoincrementing ID:改使用 distributed sequence ID,例如 UUIDV1,Twitter’s Snowflake ID 等等。
-
DDL Change:在某一 leader 修改 schema,例如
ALTER TABLE ADD COLUMN或是ALTER TABLE ALTER COLUMN。若指令本身需要 lock whole table 才能運作,那就會需要 global leaders lock。否則只將 DDL Change 複製到其他 leaders 就好。 -
Trigger on slave:在 multi-leader replication 下使用 trigger,可能會造成重複的問題。例如 database 中有一 trigger 會在表 A 修改欄位後寫入一筆紀錄到表 B。假設 leader 1 修改表 A 後 trigger 而新增一筆紀錄到表 B,表 A 的修改與表 B 的修改都會被 replica 到 leader 2,而 leader 2 的 trigger 又會因為表 A 的修改而新增一筆紀錄到表 B,造成重複。因此在 multi-leader replication 中不能使用 trigger。
-
Automatic Conflict Resolution
因為 resolve conflicts 的方式很多,而自己實作有時容易有 error 發生,而在某些情況下衝突是可以自動被解決的,以下有幾種方案:
- Conflict-free replicatec datatypes (CRDTs):可以自動 resolve conflicts 的 data structure。Riak、Redis 中都有實作 CRDTs 來自動 resolve conflicts。
- Mergable persistent data structures:透過紀錄 version history,提供 three-way merge 的能力。
Three-way merge 是指除了兩個版本之外,再多加上一個 LSA(Base)的版本一起做比較(因此 CRDTs 是 two-way merge)。例如 Git 就是使用 three-way merge。 - Operational transformation:常被用於共同編輯的算法。
Multi-Leader Replication Topologies
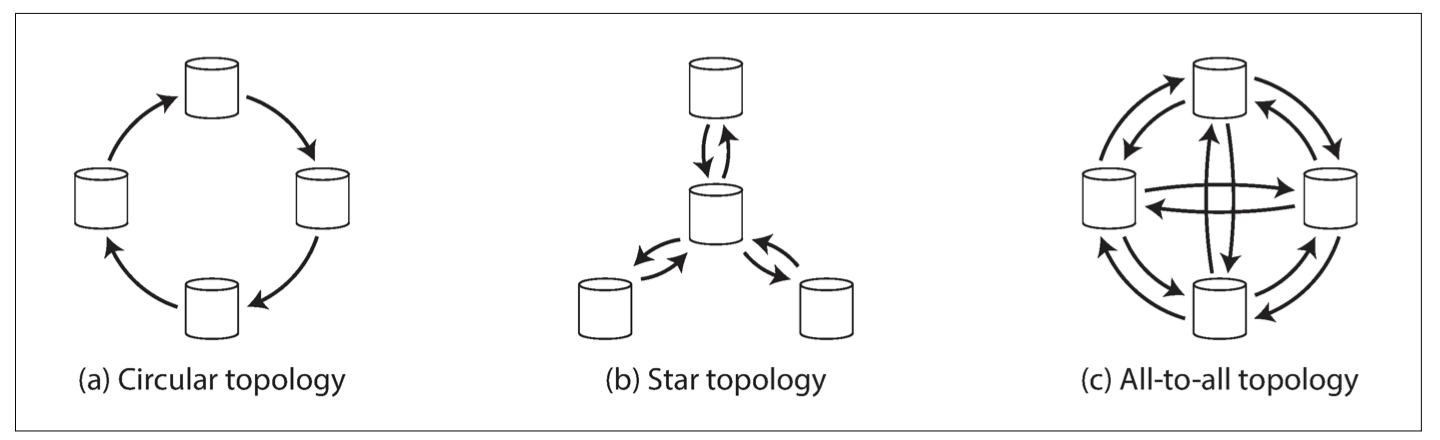
使用環狀、星狀拓樸,寫入可能會經過同一個 node 多次,因此每個節點需要在自己處理過的資料上面加上自己的 node ID 的 tag。並且若一個節點 fail 可能會導致整個 cluster 無法運作。
所以 multi-leader replication 比較喜歡採用 all-to-all 的拓樸形式,但是這種模式可能導致因果關係的順序有誤(環狀、星狀都一定不會有)。如下圖:
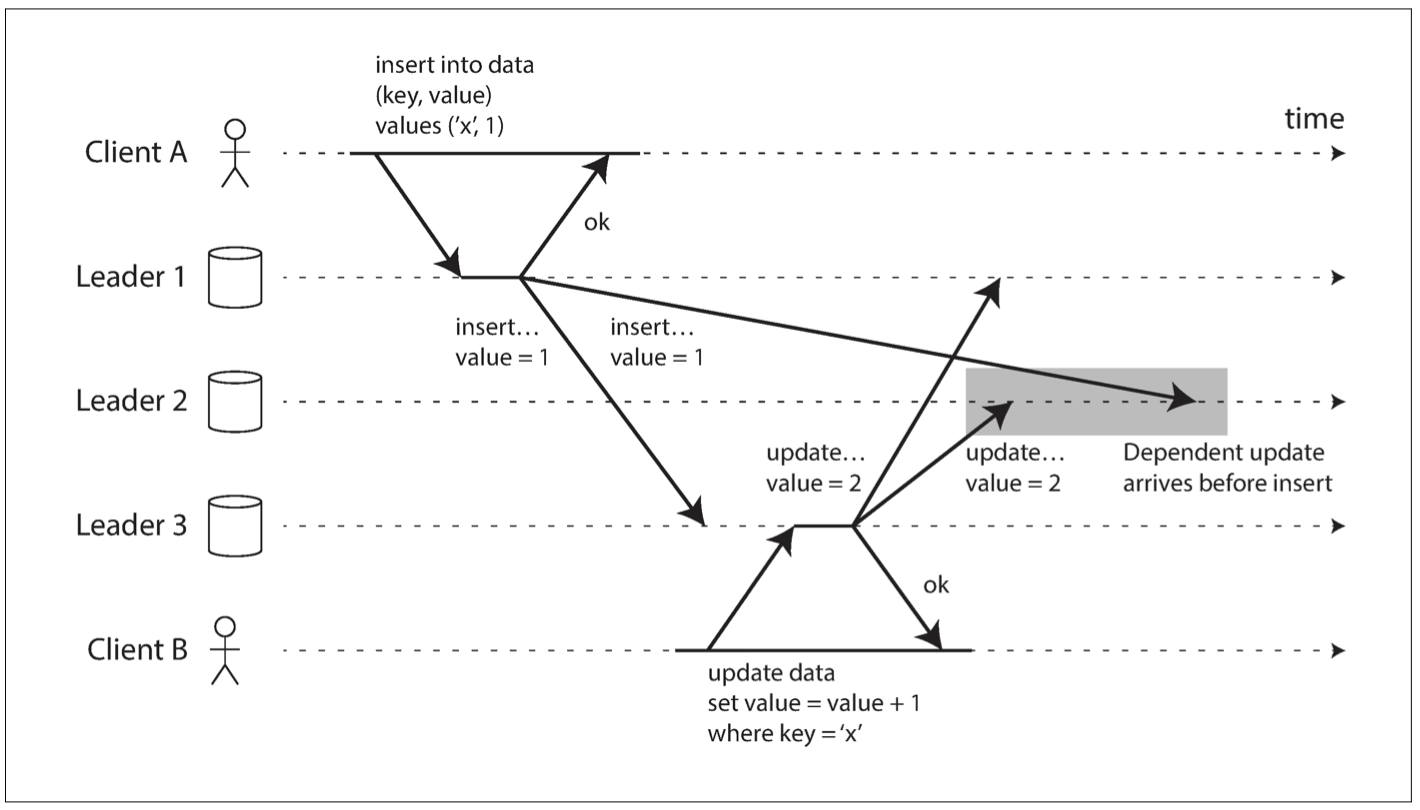
可以透過 version clock 來解決 consistent prefix reads 的問題。
Leaderless Replication
每個 replication 都允許讀寫。最著名的 leaderless replication 應用是 Dynamo。根據這篇 paper 的想法,有了 Riak、Cassandra、Voldermort 等 opensource 的 leaderless replication database。
Writing to the Database When a Node Is Down
Read repair and anti-entropy
在 leaderless replication 中,寫入操作會一次寫到 N 個節點(N 不需要等於節點數量)。先不考慮 concurrent writes 的問題,假設有一節點正在重啟,那麼寫入操作會略過此節點的寫入。當此節點重啟完畢後,有以下兩個問題:
-
若 client 從此節點讀資料,可能會讀到舊的資料。
解決辦法:一次從多個節點讀取,透過 version 就可以知道哪個是最新的資料。 -
此節點要如何同步沒更新到的資料?
-
Read repair:當 client 讀到舊的資料時,做一個寫入到 replica。適合大量 read 的情境。
-
Anti-Entropy:用一個背景程序不斷檢查兩個節點之間的資料。會有 delay,但是很少被讀到的資料也能被同步。
Merkle Tree
如何快速的比對兩個節點之間的資料呢?可以透過 merkle tree(雜湊樹)這個資料結構。
IH: internal hash functionLH: leaf hash functionS1, S2, S3, S4, S5: data
每個節點都對資料創建一個 merkle tree,因此若兩節點資料相同,只需要
O(1)的時間就可以確認。若兩節點有一筆資料不同,也只需要O(logN)的時間就可以找到不同的資料。1
2
3
4
5
6
7
8
9
10ROOT=IH(H+E)
/ \
/ \
H=IH(F+G) E
/ \ \
/ \ \
F=IH(A+B) G=IH(C+D) E
/ \ / \ \
/ \ / \ \
A=LH(S1) B=LH(S2) C=LH(S3) D=LH(S4) E=LH(S5)
-
Quorums for reading and writing
若每一筆資料有 N 個副本,只要保證每次寫入 個副本並且每次讀入 個副本且 ,則根據鴿籠原理至少有一個 read 可以讀到最新的資料。
在 dynamo-style 資料庫中, 通常都是可以調整的,常見的配置是 。只要節點數量 ,系統就可以繼續運行。例如 則可以容忍 2 個節點的 failure。
Quorum
注意,在 Dynamo 的 paper 中提到的 quorum 與 wiki 上的 quorum 解釋上面有些不同。
Wiki 上面的 quorum 利用 lock 會在 read/write 操作前進行 lock 的動作,因此若設置 ,則讀與寫不可能並行。若再加上 的條件,則寫與寫也不可能並行。如此一來即可保證 serializability。
但是在 Dynamo 的 paper 中並沒有提到要做讀寫之前需要 lock, 只是用來確認寫入與讀取的節點數量而已,因此在 paper 中也有提及是使用 quorum-like technique 而已。因此 dynamo-style 的資料庫就算設置 也通常不保證 linearizability。
Limitations of Quorum Consistency
採用 quorum 可能會有以下的問題:
- 透過設置更小的 ,可以提高系統的可用性以及降低延遲,但就有可能會讀到舊的資料。
- 兩個寫入操作可能會造成衝突。在 文章後段 會介紹 LWW 與 MVCC 的做法來解決衝突。
- 如果寫入操作在一些節點成功一些失敗,並且最後只寫入少於 個節點並回傳失敗。這些成功的寫入並無法被 rollback 造成資料不一致。
- 就算採用 ,dynamo-style 的資料庫並不保證 linearizability。
![Reader B read stale value although strict quorum is applied.]()
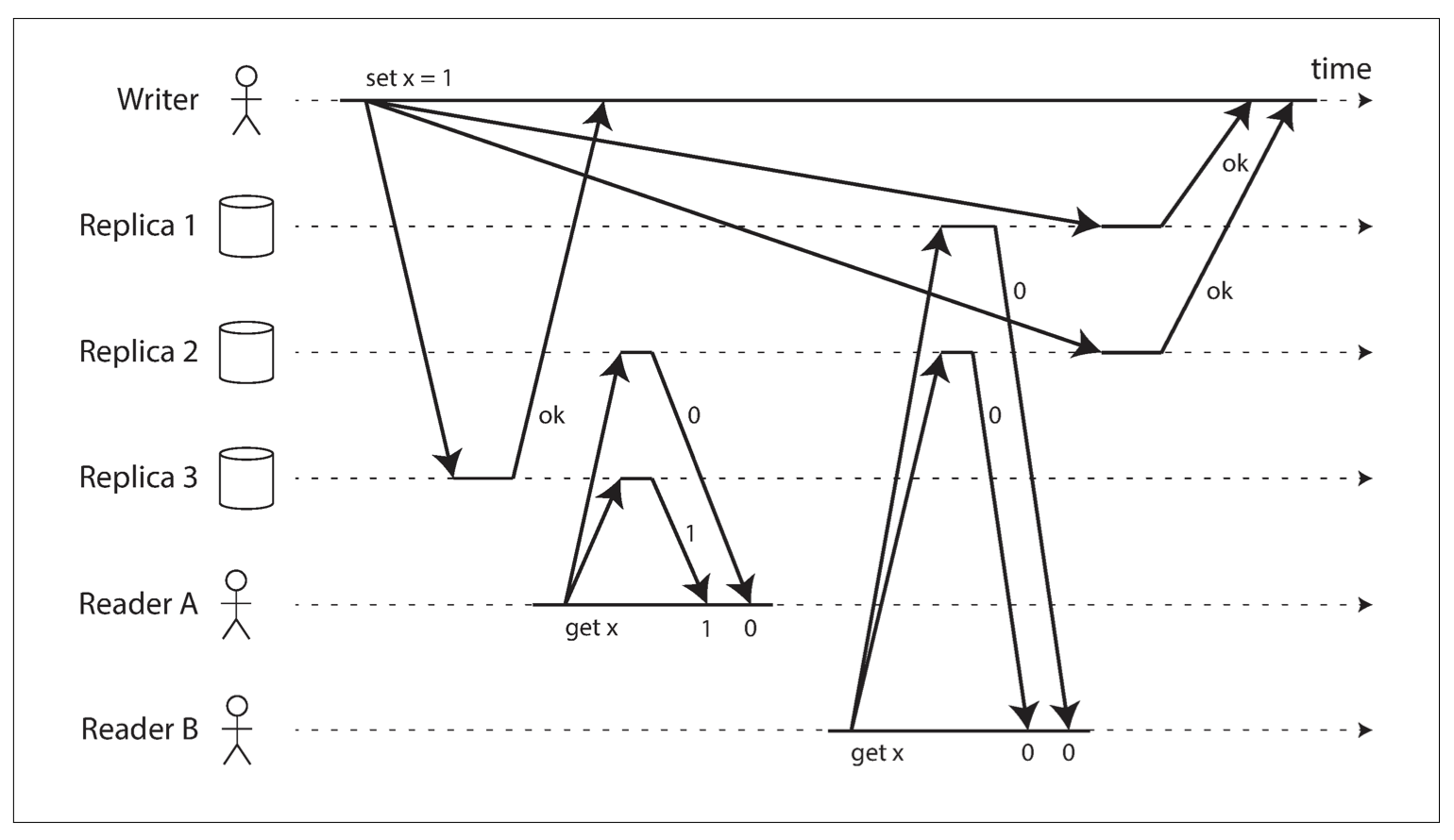
因此雖然正常情況下使用 的 quorum 配置可以確保讀到最新的值,但是實際上並沒有那麼簡單。Dynamo-style 資料庫通常需要應用能夠容忍最終一致性,而 的配置可以用來調整讀到舊資料的機率。
Sloppy Quorums and Hinted Handoff
一般情況下,database cluster 會有很多節點,而每個寫入操作只需要 個副本,透過 consistent hashing 可以決定資料要被寫到哪 個節點。
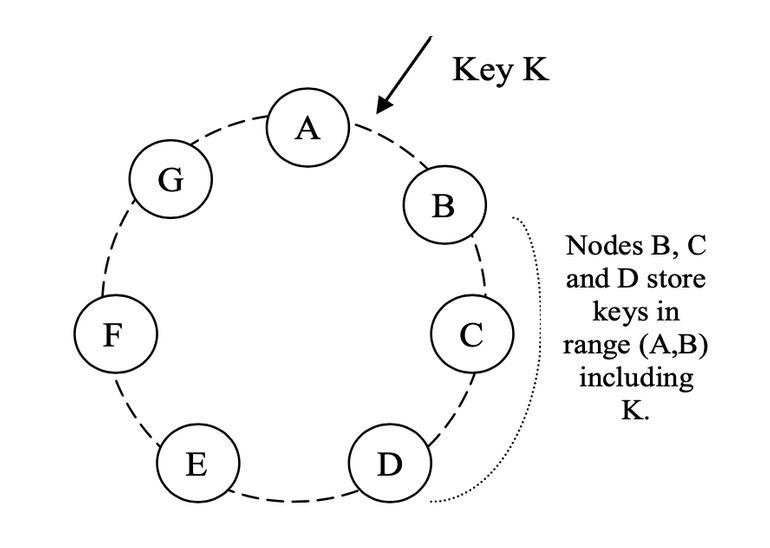
若 client 因為網路問題無法連接到這 個節點,我們可以回傳 error 告知失敗。或是允許寫入到這 個節點以外的節點,稱作 sloppy quorum。
例如上圖,資料要被寫到 A、B、C 節點。當 A 節點不可用時,可以先暫時寫入到節點 D 的獨立儲存空間,並且紀錄原節點是 A 節點。如此一來當 D 節點發現 A 節點恢復時,就會將資料重新寫回 A 節點並將 D 節點內的資料刪除。這種方式就稱作 hinted handoff。
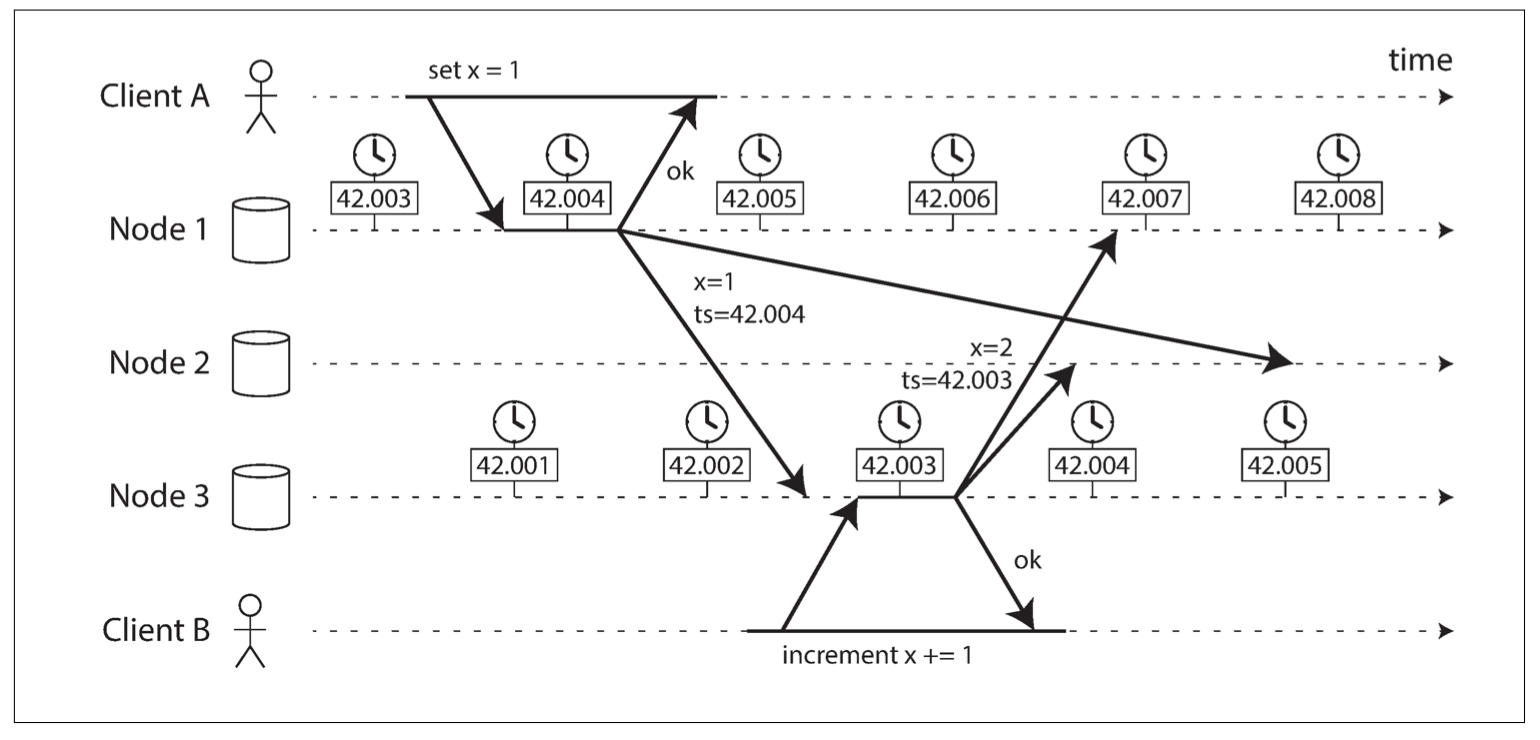
Detecting Concurrent Writes
考慮兩個 clients 想寫入 set(x, 1) 與 set(x, 2),因為網路速度的不同,不同節點可能收到不一樣的順序,導致最後兩個節點的資料是不一致的。
因此這裡介紹 LWW 與 MVCC 兩種方式:
Last write wins
在每個 writes 上面都附加一個 timestamp,當 conflict 發生時,選擇較新的 write。LWW 可以達成最終一致性,但壞處是會造成資料的遺失。
由於在分散式系統下每個節點的時間都是不一樣的,因此甚至可能造成有因果關係的 writes 的時間是對調的。
Cassandra 即選擇 LWW 來解決衝突,至於為什麼 cassandra 不選擇接下來要介紹的 vector clock,可以參考這篇 Why Cassandra Doesn’t Need Vector Clocks。
MVCC
MVCC 的想法為如果有衝突發生,那麼就偵測衝突並且保留全部的版本,在下一次 client 讀取這筆資料時就將全部版本返回交由 client 來解決衝突。
所以首先要定義對於同一筆資料何謂衝突?Concurrent write 這個詞彙看似指的是時間上的同時發生,但若把時間的粒度縮小來看兩個寫入並不會完全同時發生。因此 concurrent write 的定義應該是兩個寫入是沒有因果關係的,因此這兩個寫入誰先誰後都沒有問題,所以才會照成衝突。
使用 vector clocks/version vectors 為每個 key 維護多個版本號碼,當發生衝突時都保留。
這種做法可以保證資料不會遺失,但是 client 必須自己解決衝突。
Dynamo 的 paper 中即使用此方法來偵測衝突的發生,Voldermort、Riak 都是採用此做法。
Summary
總結 replication 帶來的好處有:
- High availability:就算有部分節點停止也能正常運作。
- Latency:透過縮短地理上的距離來降低延遲。
- Scalability:可以透過增加機器的數量來提升讀寫能力。
而常見的三種 replication 模式包含:
- Single-leader replication:只有一個 leader 節點並且所有的寫入操作只能透過 leader,由 leader 將資料複製到其他的 follower 節點。配置簡單且不需要考慮 concurrent writes 的問題;但只能提升 read scalability,並且要考慮 leader failure 的問題
- Multi-leader replication:有多個 leader 節點,適合在 datacenter 使用以降低寫入的 latency,有更高的可用性。但是必須處理 concurrent writes 的問題。
- Leaderless replication:可以在任何 nodes 進行讀寫,有更高的 availability 以及更低的 consistency,適合能容忍 eventual consistency 的應用使用。
對於 replication lag,使用時要考慮是否能接受 eventual consistency,否則需要考慮提高 consistency level:
- Read-after-write consistency:使用者必須讀到自己寫入的資料。
- Monotonic reads consistency:讀到的資料不能回朔。
- Consistency prefix reads consistency:有因果關係的資料要正確。
本文的圖片來源(Image credits):
最後,如果你喜歡這篇文章,或是文章對你有幫助的話,可以幫我按個喜歡、或是留言!你的支持就是我寫作的最大動力。有任何想問的問題也可以在底下留言喔~