Designing Data-Intensive Application 第二章筆記
本章節主要在介紹目前主流的三個 Data Model,Relational Model、Document Model 以及 Graph Model 的優缺點、演進史以及使用時機。
Data Model 是一層疊一層的:
- 在應用層,資料可能是購物車資訊、金流、商品等在現實世界中的資訊。
- 在後端,我們必須把資料轉換成易於儲存的資料結構,可能是 XML 或 JSON,又或是關聯式資料庫中的 Tables。
- 在資料庫中,XML、JSON 或是 Tables 都必須轉變成 bytes 的形式,使他們能夠被儲存在 memory 或是 disk 上。
- 在硬體層,bytes 必須轉換成電流、磁場等等。
層與層透過定義好的 API 來溝通,可以將背後的複雜實作藏在 API 之後。
各種不同的 data model 背後都會一些使用情境的假設,因此每一種 data model 都有不同的功能、操作,對於支援的操作,效能也有好與壞之差別。
也因為要精通一種 data model 是十分困難的(光是 relational data modeling 就有這麼多書籍),因此在使用之前先綜觀的了解每一種 model 的優缺點以及使用時機是非常重要的。
Relational Model Versus Document Model
Relational model 在 1970 年時被提出,在 1980 年代開始被廣泛的使用直到現在。當時與其競爭的還有 network model 以及 hierarchical model,但是後來都被 relational model 主宰,而 relational model 之所以能夠成功主要因為兩點:
- 其將複雜的 query 實作藏在 database 本身的 query optimizer 中,提供更乾淨的介面使用,讓開發者不需知道資料是如何被儲存在資料庫中的。
- 其解決了當時一個重要的問題:多對多的關聯。
The Birth of NoSQL
NoSQL 在 2010 年初期走紅,當時 NoSQL 指的是非關聯式、開源、分散式的資料庫。後來轉變成 Not Only SQL。
NoSQL 最主要的推力在:
- 有更好的 Scalability。
- 支援一些關聯式資料庫不支援的操作。
- 可以使用更彈性、更自由的儲存資料結構。
The Object-Relational Mismatch
稍微介紹完了 Relational Model 跟 Document Model 的出現與歷史,接下來講 Relational Model 最主要遇到的問題:Object-Relational Mismatch。
大多數的應用程式開發都是 object-oriented programming,因此在 object 與 table 之間的轉換會遇到困難,幸好現在主流的 database 都有 Object-relational mapping (ORM) 框架的幫助來減少這些轉換的複雜性。但是當原資料就是不太適合放進 table 時,就會遇到困難。
這裡舉履歷為例子(LinkedIn Profile),一個使用者會有一個 unique ID user_id,會有姓 last_name 與名 first_name,這些欄位都是一個值,可以被當作 users 表的欄位。
但是一個使用者可能有多個工作、學歷、甚至是聯絡資料,這些一對多的關聯在 relational model 中有幾種處理方式:
- 將工作、學歷、聯絡資料放到另一張 table 來儲存,這也是最常見的資料庫正規化方式
- 一些關聯式資料庫支援 Array 或是 JSON 儲存格式,例如 PostgreSQL。
- 直接將 JSON 或是 XML 格式編碼成 bytes 再儲存進資料庫的一個欄位。
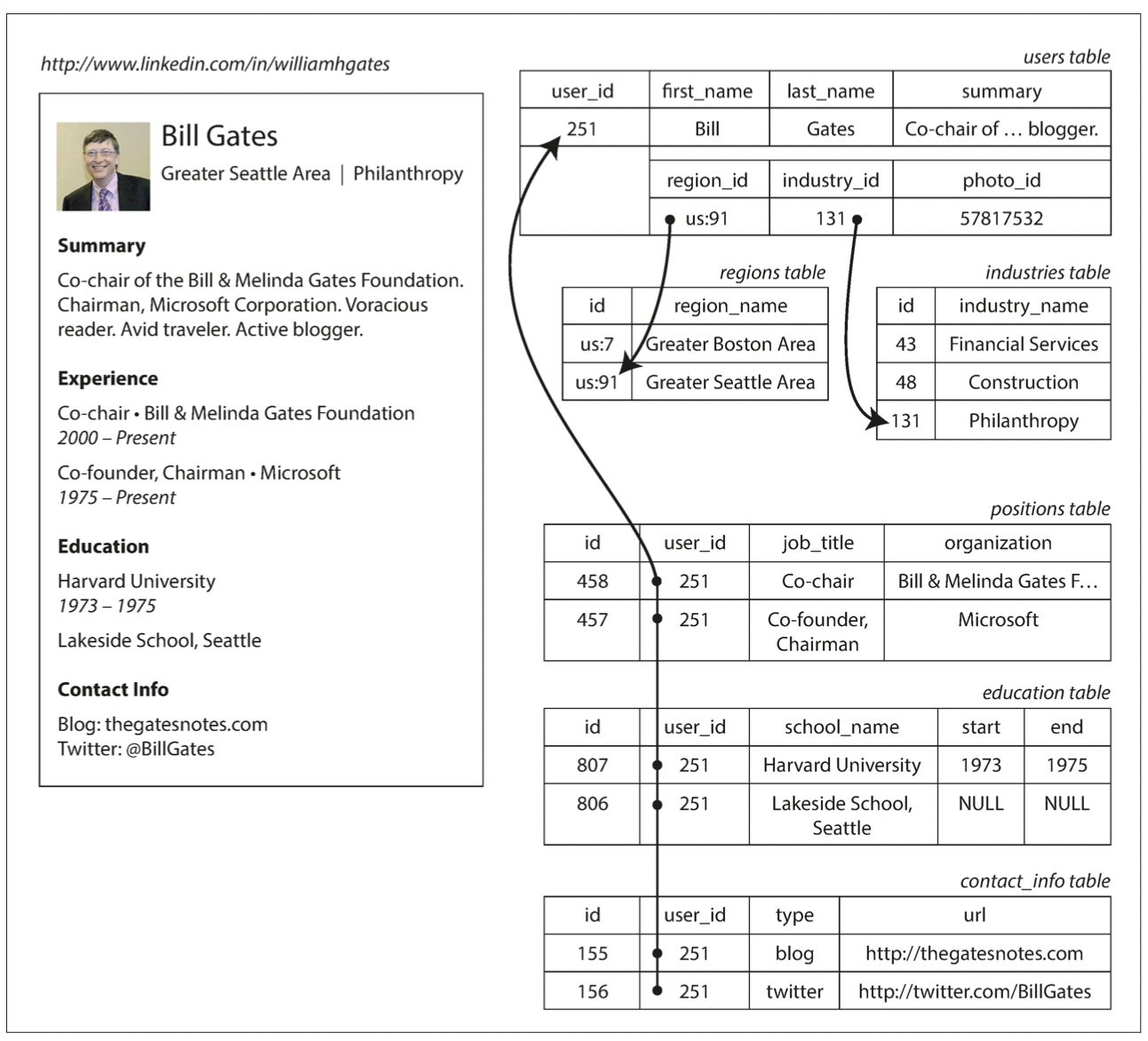
履歷的資料就比較適合放在 JSON 格式下,例如:
1 | { |
由上面的圖與 JSON 可以看出,JSON 格式有更好的 locality,使用 relational model 就必須使用多次的 Join 來關聯多個資料庫,而 JSON 中所有與此使用者相關的資訊都儲存在一起,一個簡單的 query 就能達成。
Many-to-One and Many-to-Many Relationships
講完了 relational model 的缺點,再來講 document model 的缺點。
首先,可以發現上面的 JSON 中 region 與 industry 都只儲存了一個 ID,而不是直接儲存字串,這樣做有幾個好處:
- 一致性,避免相同意思但是拼法不同的問題
- 易於更新,當一個名稱變更時,只需要修改一處的名字
- 支援多語系,可以透過唯一的 ID 將其翻譯成各個語系的字串
- 更好的支援搜尋功能
使用 ID 的好處在於 ID 對於人是沒有意義的,因此 ID 永遠不會改變。因此透過 ID 將重複的資料都變成唯一的 row,可以避免更新、刪除時需要更新到多個 rows 的問題,這就是資料正規化的核心想法。
在 relational database 中,多對一的關係很好處理,透過 ID 加上 join 的操作即可。在 document database 中,一對多關聯可以直接的儲存(像 JSON 中的 Array 即是一對多關聯),因此 document model 通常不支援 join 的操作,則可能需要在應用層手動的模擬 join 的操作。
在 document model 中,不一定要像 relational model 一樣透過 ID 做多對一的關聯,可以透過 denormalization,直接讓資料重複的出現,例如直接將 JSON 中
region_id直接用region的 object 取代。好處是不需要再有 join 的操作,壞處當然就是喪失上面提到只儲存 ID 的幾個好處。這個方法比較適合用在很少被更改的資料,因為 denormalization 會使得 update, delete 的操作變得更複雜與更沒效率。在 MongoDB 的 6 Rules of Thumb for MongoDB Schema 就有提到這個方法的使用時機與考量,建議讀者可以閱讀~
另外,就算資料原本很符合 document model 的格式,在未來也有機會因為需求的變更變得更加複雜而產生多對一、多對多的關聯。例如:
- 新增學校的 logo、聯絡電話、地址等等,這時不再只能儲存一個
school_name字串,就可能需要有一個schools的表來儲存資訊,如此一來users與schools就變成多對一的關係了。 - 新增一個推薦功能可以讓使用者爲另一名使用者寫推薦信,則產生了多對多的關係。
Are Document Databases Repeatng History
講完了 relational model 與 document model 各自的不擅長之處,這裡稍微講古一下 network model 與 hierarchical model。
在 1970 年最熱門的資料庫 IBM’s Information Management System (IMS) 採用的是 hierarchical model,與現在 document model 中 JSON 的格式非常相似。與現在使用 document model 一樣,hierarchical model 可以很好的處理一對多關聯,但是不適合處理多對一或是多對多關聯。
因此兩個最突出的解決方案出現了,分別是 network model 以及 relational model。
The network model
Network model 是由一個會議 Conference on Data Systems Languages (CODASYL) 制定的,因此也叫做 CODASYL model。
Network model 與 hierarchical model 很像,最大的不同在於每個 record 可以有不只一個 parent。
在 network model 中的 query 必須透過指針從 root 移動到想要的 record,開發者必須自己維護可能走到重複的點、決定路徑等問題。
The relational model
Relational model 將資料放在表中的列上,最成功的部分在於 relational model 把 query 的複雜實作都抽象化在 DBMS 的 query optimizer 中,使得開發者可以簡單的選擇想要的資料,透過 query optimizer 自行決定要怎麼存取資料、要使用哪個 index。
Comparison to document databases
最後回到最初的問題,那麼現在的 document model 是否是重蹈覆轍呢?
現在的 document model 可以透過類似 relational model 中 foreign key 的方式,來關聯多對一或是多對多的模型,稱作 document reference。不像是之前 network model 所採用的方式。
最終要如何選擇,到底是 relational model 還是 document model 更符合使用情境,還是看各位開發者的決定了!
Relational Versus Document Databases Today
最後總結一些今日 relational 與 document databases 在 data model 上的比較。
Which data model leads to simpler application code
跟在前面提到的一樣,如果資料是 document-like,並沒有多對一、多對多的關聯,則較適合 document model。
若有很大量的多對多關聯存在,甚至 relational model 也並不是最適合的選項,後面會介紹到 graph model 就是專門解決這個問題而產生的。
Schema flexibility in the document model
通常 document databases 會被叫做 schemaless,但更準確來說應該稱作 schema-on-read,也就是資料的格式是隱藏、不需預先定義的,在讀出時才決定他的格式。
當儲存的資料結構需要改變時,例如將原本的 name 欄位拆成 first_name 以及 last_name,document model 可以很簡單的透過應用層的程式碼在讀出與寫入時對資料做出改變即可,因爲 document databases 通常容許一個 collections 內的資料長相不同。
1 | if (user && user.name && !user.first_name) { |
而 relational database 通常必須透過 migration 來達成:
1 | ALTER TABLE users ADD COLUMN first_name text; |
ALTER TABLE 對於大型系統而言是非常可怕的,通常會造成 database 的 downtime。PostgreSQL 在 v11 之前,ALTER TABLE ADD COLUMN 會拿整張 table 的 ACCESS EXCLUSIVE lock,造成所有的 transaction 不能 access 這張 table。
因此若資料結構是經常改動、或是資料的結構變化很大,則有 schema 反而會成為一種困難,document model 可能會更加適合。
Data locality for queries
Document model 通常將整個 document 儲存成一段 encoded 的 JSON 字串(或是 MongoDB’s BSON),因此存取會整個 document 一起取出,也就是 document model 的 storage locality。
若資料經常是整個被存取的,則 document model 可以避免掉 relational model 因為需要多次 join 而可能造成多次 disk access 的問題。但反之若每次只需要一小部分的資料,document 還是會被整個 load 到 memory 造成浪費。並且 document 更新時通常也是整個 document 一起寫入,因此就算只修改一小部分的資料也會重寫整個 document。
Convergence of document and relational databases
PostgreSQL 從 v9.3 開始、MySQL 從 v5.7 開始支援 JSON 格式的欄位。
MongoDB 的 driver 會自動的 join document reference。
因此 relational 與 document databases 現在是越來越相近的,讓使用者在應用層能夠更方便的挑選適合的 data model。
Query Languages for Data
這個段落開始介紹 declarative language 與 imperative programming 的差異。
Declarative language 即只描述目標的性質,不須描述要如何達到此目標。而 imperative programming 則是很像一般的 programming language,要達到目標的話一定要將流程寫出。
簡單來說:declarative 是定義 what to do、而 imperative 是定義 how to do。
舉例來說 SQL 就是一種 declarative language、CSS 也是一種 declarative language。
而資料庫更適合 declarative language,因為可以把實作的複雜都隱藏起來,讓 DBMS 決定如何優化,並且更適合做平行化的處理。
MapReduce Querying
MapReduce 是 google 提出的處理大量資料的一種 programming,同時用到了 declarative 與 imperative 的方式。
1 | db.observations.mapReduce( |
因為 MapReduce 需要使用者自己小心的撰寫 Javascript 程式碼,雖然可以做到很複雜的操作,但對於簡單的操作來說,還是 declarative language 更適合作為資料庫的查詢語言。
因此 MongoDB 在 v2.2 之後支援了 aggregation pipeline 的 declarative query language。
1 | db.observations.aggregate([ |
Graph-Like Data Models
當資料庫有很多的多對多關聯,就很適合使用 graph-like data model。
Graph 中包含點與邊,在現實中的例子包含:
- Social graphs: 點代表人,邊代表朋友或是追蹤關係。
- The web graph: 點代表網頁,邊代表連到別的網頁的 link。
在一張 graph 中每個點與邊也可以代表不同意義,例如 Facebook 維護了一張 graph,其中 vertex 可能是人、地點、事件或是留言,而邊可能代表人參加的事件、事件發生的地點或是人留下的留言。
Graph-like data models 主要分為兩種,property graph model 以及 triple-store model。
Property Graphs
每個點都有:
- 一個 unique ID
- 一些出邊
- 一些入邊
- 一些 properties(key-value pairs)
每個邊都有:
- 一個 unique ID
- 邊的起點跟終點
- 一個 label
- 一些 properties(key-value pairs)
The Cypher Query Language
Cypher 是一種 declarative language,是 Neo4j 圖資料庫的查詢語言。
1 | CREATE |
1 | MATCH |
() 代表點、[] 代表邊、: 代表邊或是點的 label、{} 內的代表 properties、-> 代表邊的方向,() 或是 [] 中最前面的變數則是命名。
Graph Queries in SQL
作者提出如果把 graph data 放在 relational structure 內,那麼可以使用 SQL 來做查詢嗎?
可以觀察到上面的 query 有一個特別的符號 *0..,這代表的 label 是 WITHIN 的邊可以出現 0 到任意多次,但是在 SQL 中,並沒有辦法指定 0 ~ 任意多次的 join,要做到的話必須透過 SQL 中的 RECURSIVE 語法,更加複雜。
Triple-Stores and SPARQL
Triple-Stores 透過三元組 (subject, predicate, object) 來儲存資料。例如 (Jim, likes, bananas)。
三元組也可以用來描述 subject 的 properties,例如 (Jim, age, 33)。
對應到圖的話,則 subject 是點、predicate 是邊、object 可以是點或是值。
The SPARQL query language
1 | SELECT ?personName WHERE { |
Graph Databases Compared to the Network Model
Network (CODASYL) model 與現今的 graph databases 看起來十分相似,但是 graph databases 能成功大致有幾個原因:
- CODASYL 沒有可以直接 access record 的方式,但是 Graph Model 中每個 vertex 跟 edge 都有 uid 可以直接 access。
- CODASYL 並沒有 declarative query language(ex: Cypher),因此不好做查詢。
總結
因為每一種 data model 都很複雜,因此本章先以綜觀的角度看各種 data model 的性質與優缺點,期望開發者能夠在使用這些 data model 時爲各種情境的應用挑選正確的資料模型。
最後,如果你喜歡這篇文章,或是文章對你有幫助的話,可以幫我按個喜歡、或是留言!你的支持就是我寫作的最大動力。有任何想問的問題也可以在底下留言喔~