Designing Data-Intensive Application 第一章筆記

Introduction
現在的軟體基本上都不是 CPU Bound,而是 Data-Intensive 的,也就是大多數的瓶頸都在資料的量而不是計算的量。因此大多數的應用程式會依靠多種工具來滿足不同情境下的資料使用。
例如一個後端可能會用到 MySQL、PostgreSQL 來儲存資料,用 Redis 來做快取,用 ElasticSearch 來做搜尋引擎,用 RabbitMQ、NATS 來做異步的消息傳輸。有各種工具可以滿足不同需求的資料使用方式,因此我們需要知道在設計不同需求的系統時,要如何挑選、使用這些技術與工具。下圖即是一種可能的系統架構:
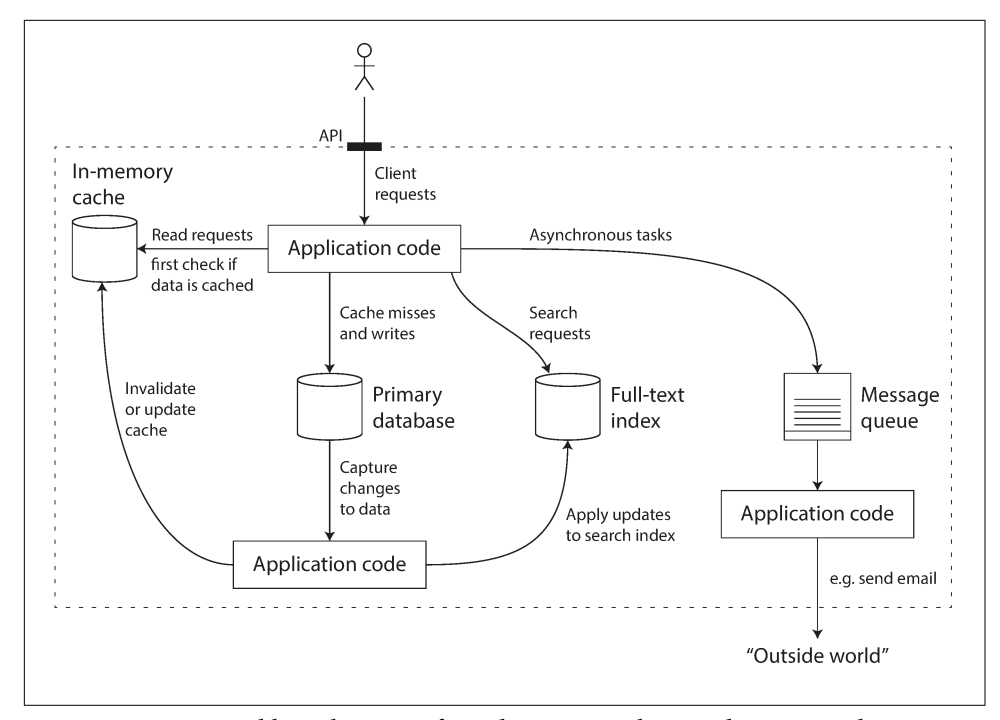
本章節重點先放在三項設計系統時的要點:可靠性(Reliability)、可擴展性(Scalability)以及可維護性(Maintainability)。
Reliability
一個系統是可靠的,如果能夠功能正常的運作、容錯(Fault Tolerance)、有好的效率(Performance)以及可以避免被攻擊。
這裡特別提到 fault 指的是系統背離原本預期的行為,而 failure 指的是整個系統因為錯誤而停止服務。因為任何的系統都不可能是完全不會有錯誤發生的,因此我們應該設計一個 fault tolerance 的系統來避免 failure 的發生。
另外,作者提到可以透過故意的產生錯誤來檢查系統是否能夠應付這些錯誤,例如 Netflix 的 Chaos Monkey 會隨機的關掉 VM 的容器,強迫工程師建立更能容錯的系統。這就是所謂的 Chaos Engineering。
Hardware Faults
硬碟的 Mean Time to Failure(MTTF) 在 10 ~ 50 年之間,因此一個有 10000 個硬碟的叢集平均每天都會有一顆硬碟故障。
避免硬碟故障導致的問題,可以使用 RAID 磁碟陣列。另外各種硬體都有可能發生錯誤,因此都需要有備援機制。
不過筆者認為現在大多數公司都會直接採用雲端平台提供的各種服務與資源,因此這部分的問題應該可以大量避免了。不過 GCP/AWS 每年也都會有幾次的 System Outage,因此若是服務很重要的話,可能甚至要考慮跨雲的部署或是救援。
Software Errors
軟體系統錯誤可能會導致其他系統也受到影響。雖然沒有 100% 能夠避免軟體錯誤的方法,但有很多小事情可以幫助改善,例如撰寫測試,從單元測試、整合測試到端對端測試;做監控以確定系統正常運作。
Human Errors
人類是不可靠的,據調查系統大多數都是因為人為操作失誤而導致停止運作,而因為硬體錯誤而導致的錯誤只有 10–25%。
要盡量避免人為操作錯誤,有幾項方式:
- 定義良好的抽象層、APIs、管理者介面。
- 提供一個跟非 production,但與 production 幾乎功能一致的環境。通常就是所謂的 staging server。
- 撰寫完整的測試。
- 有快速的方法可以恢復錯誤,例如 rollback changes。
- 做 monitor 以及 metrics,monitor 可以幫助提早的發現錯誤,當錯誤發生時透過 metrics 來排查。
Scalability
在思考如何應付大量的流量之前,應該先定義系統的流量。
Describing Load
舉 Twitter 為例,若只有兩項功能:
- Post tweet:使用者可以發布 tweet,所有追蹤訂閱者都會收到通知。4.6k requests/sec at average, 12k requests/sec at peak。
- Home timeline:使用者可以檢視所有的追蹤者發布的 tweets。 300k requests/sec。
有兩種不同方式可以做到 View home timeline 的功能:
-
使用 SQL Join
1
2
3
4SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user -
對每一個使用者維護一個 Cache Queue,當 tweet 發出時,將訊息送到每個訂閱者的 Queue。
一開始 Twitter 採用的是方法 1,但是當使用者多起來時,每次的 view home timeline 都要做 SQL Join,造成過多的流量。
因為使用者的平均追蹤者是 75 人,等於每次的推文平均需要 次的 cache writes,因為 post tweet 的流量是比 view home timeline 低許多的,因此 Twitter 改採用了方法 2,來降低 view home timeline 造成的 bottleneck。
但是有些使用者有超過3千萬個追蹤者,因此每次他發布推文時需要3千萬次的 cache writes,可能會造成系統的負擔,因此最後 Twitter 採取了 Hybrid 的做法,對於過多追蹤者的用戶,他們的發推就不採用第二種做法。
由這個例子就可以很輕易的知道,根據每個系統、每項功能的不同流量高低,都會有對應不一樣的設計方式。
Describing Performance
可以用以下兩點來分析系統效能:
- 當流量增加時,系統的效能會受到多少影響?
- 當流量增加時,需要增加多少資源(CPU, Memory, Network bandwith)才能使的系統效能不變。
通常評估的方式是 Response Time,從 client 發起請求到收到請求所經過的時間。
通常不會看平均,因為平均無法代表使用者真正收到的延遲時間。通常會採用百分位數(Percentile),也就是將 response time 由低到高排序後某個百分點對應的數值。
代表第k百分位數。
- 可以知道使用者通常等待的時間。
- 也可以稱作 tail latency,是比較重要的觀察點,可以用來觀察大多數的使用者的等待時間。
但也不是越多 9 就越好,因為每多一個 9 都會使得維運成本大幅增加。
在測試時,要從 client 端計算 response time,並且 requests 要同時送出,才能達到真正的效果。
Approaches for Coping with Load
在流量增加速度很快的服務下,必然可能會需要重構系統架構。
不過在不動系統架構的前提下,通常有兩種方式可以 scale up:
- Vertical scaling:增加 CPU、增加 Memory,使用更好的機器。
- Horizontal scaling:將流量分散到多台 server 上。
通常要 vertical scaling 是比較容易的,但是太高規格的機器是非常昂貴的,因此有一定流量的系統通常會無可避免的要做 horizontal scaling。將 stateless 的服務(Ex: front-end server)做 horizontal scaling 是很容易的,但是 stateful 的服務要變成 distributed system 就會衍生出很多問題,因此通常會採用 vertical scaling 直到價格無法應付。
當然因應現在資訊爆炸,資料量越來越大的情形,現在也已經有很多 distributed system 的工具與解決方案了。這些都會在後面的書中後面的章節提到。
Maintainability
沒有工程師會想要接手 legacy system,因此,保持系統的可維護性也是很重要的。
Operability: Making Life Easy for Operations
一個好的維運團隊應該要做到:
- 監控系統的健康並且如果系統陣亡能快速的復原
- 做錯誤的追蹤以及效能的追蹤,例如 request 在哪裡是 bottleneck
- 系統安全性的修補
- 建立部署、配置、管理方面的實踐方式與工具
當然還有更多,這裡只提一些筆者認為比較重要的。
Simplicity: Managing Complexity
可以利用抽象來簡化程式的複雜度。
Evolvability: Making Change Easy
系統是不會永遠不變的。Aglie 敏捷開發方法即是採用一種擁抱改變的態度,其中還提出了例如 TDD(Test-Driven Design)與 Refactoring 的方法。
Summary
設計系統時三個重要的觀點,可靠性(Reliability)、可擴展性(Scalability)以及可維護性(Maintainability)。
- Reliability:系統要可以容錯。
- Scalability:系統負載增加時也能保持性能。
- Maintainability:降低工程師與維運團隊工作的複雜度。
最後,如果你喜歡這篇文章,或是文章對你有幫助的話,可以幫我按個喜歡、或是留言!你的支持就是我寫作的最大動力。有任何想問的問題也可以在底下留言喔~